Le principe du référencement SEO repose sur le fait que les robots de moteur de recherche puissent explorer, analyser, classer et… référencer les pages de votre site web. Atteindre la première position sur Google est le saint graal lorsque l’on travaille son SEO. Mais il arrive dans certains cas qu’une page soit plus intéressante lorsqu’elle n’est pas référencée.
Imaginez que vous souhaitiez entrer dans un bar qui, auparavant, était ouvert à tous, mais a fini par fermer son entrée (il n’est plus accessible pour Google). Pour entrer dans ce bar, il faut simplement connaître l’entrée secrète (l’URL de votre page) pour avoir accès à l’ensemble du bar (votre site). Concrètement, le fait de ne pas référencer votre site internet ressemble plus ou moins à cela, mais il existe des nuances.
Vous vous demandez comment procéder pour ne pas référencer une page ? Voyons voir cela de plus près.
Dans quel cas est-il intéressant de ne pas référencer une page ?
Contrairement à ce que l’on peut penser, ne pas référencer une page peut être très intéressant selon différentes situations.
Mon site ou mes pages sont en construction
Si vous venez de créer votre site web et que ses pages sont en cours de construction, vous n’avez pas nécessairement envie que votre site soit trouvable par l’internaute pour le moment.
Dans ce cas de figure, bloquer le référencement de votre site fait sens.
Dans notre exemple : inutile d’ouvrir l’accès au bar si l’intérieur est en cours de construction, vous préférez attendre que le bâtiment soit présentable à la clientèle.
Eviter le contenu dupliqué
Ce cas-là est un peu plus particulier, puisque ce n’est pas tant le référencement de vos pages qui vous importent que le fait de ne pas recevoir de pénalités pour contenu dupliqué. Si, sur une fiche produit, vous avez plusieurs variations du même produit (donc différentes pages) mais qui possèdent sensiblement le même texte, cela peut poser problème. À ce moment-là, vous allez plutôt chercher à référencer une page “principale” (c’est-à-dire la variation de votre produit qui vous paraît la plus intéressante) pour ne pas poser problème à Google.
Les fichiers PDF qui ne devraient pas être trouvables sans connexion
Il arrive dans de plus rares cas que vous souhaitez tout simplement “invisibiliser” des ressources de votre site web pour les moteurs de recherche.
C’est notamment un cas que j’ai déjà rencontré auprès d’un de mes clients : son site possède des fichiers PDF qui ne devraient être accessibles que par une connexion à l’intranet. Malheureusement, ces fichiers sont accessibles avec une recherche « site:https://site.fr/ »
Un contenu du site a vocation à rester privé
C’est plus ou moins la même chose que le point précédent. Lorsque vous souhaitez qu’une page ou une ressource reste accessible à une minorité de personne, via un lien par exemple, vous allez chercher à invisibiliser son accès au plus grand nombre.
Dans notre exemple : votre bar est un bar clandestin. Seuls ceux qui connaissent l’accès sont les bienvenus.
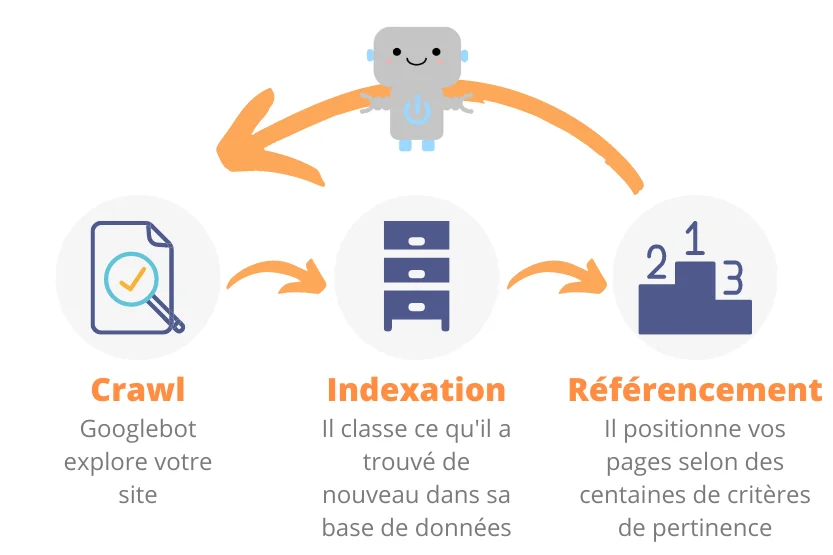
Quelle différence entre crawl et indexation ?
Maintenant vous savez plus ou moins dans quel cas de figure il est intéressant d’avoir recours au non-référencement de vos pages.
Il est nécessaire de distinguer les différentes étapes qui permettent le référencement de vos pages :
- le crawl, qui représente la capacité des robots des moteurs de recherche à explorer votre site web. concrètement, c’est la phase où les moteurs de recherche découvrent et explorent vos nouvelles pages
- l’indexation, c’est lorsque les moteurs de recherche rangent et classent vos nouvelles pages oui modifications qui ont été apportées aux anciennes dans leur index, c’est-à-dire leur base de données qui permettront pas la suite de référencer vos pages selon quelques centaines de critères
Quelle différence entre référencement et indexation ?
L’indexation, c’est le fait qu’un robot d’indexation (ils sont souvent nombreux) classe tous les changements faits dans vos pages dans la base de données du moteur tandis que le référencement, c’est le fait de classer, d’évaluer et de faire ressortir vos pages dans leurs résultats de recherche. Dans ce cas, on dit qu’une page qui est dans les premières positions est une page qui est bien référencée.
Vous l’aurez compris, les 3 étapes présentées ici se succèdent les unes aux autres. Vous souhaitez empêcher le référencement d’une de vos pages, la méthode la plus efficace sera d’empêcher le crawl ou l’indexation.
Comment empêcher une page d’être référencée ?
On arrive au cœur du sujet : finalement, comment faire en sorte qu’une page ne soit pas référencée ?
Il existe plusieurs méthodes pour parvenir à ce résultat. Commençons par les plus courantes.
La balise noindex
La balise noindex est à ajouter directement dans vos pages. Elle permet d’indiquer au moteur de recherche que vous ne souhaitez pas qu’il indexe chaque page qui possède cette balise.
Cette balise est à insérer dans le code source vos pages web. Cette balise doit prendre la forme suivante :
Si vous souhaitez bloquer l’indexation pour des robots en particulier, vous pouvez toujours modifier le meta name en remplaçant “robots” par le nom du robot en question.
C’est la méthode la plus simple pour procéder (il vous suffit simplement d’accéder au code source de votre page).
A contrario, si vous avez de nombreuses pages sur votre site web que vous souhaitez ne pas référencer (admettons plusieurs variations de nombreuses pages produits) alors ce n’est peut-être pas la méthode la plus adéquate car elle pourra être très chronophage.
De manière globale, la balise noindex est prise en compte lorsque Google passe de nouveau sur votre site web et crawl la page. Il note alors la nouvelle directive et le changement sur cette page.
L’entête HTTP X-Robots-Tag noindex (.htaccess)
Une autre manière de procéder nécessite que vous ayez accès à votre fichier .htaccess. Si vous avez un accès FTP à votre site web, cela ne devrait pas être trop compliqué à trouver.
En revanche, si vous ne pensez pas avoir de compétences suffisantes, ne modifiez pas ce fichier, cela pourrait s’avérer dangereux pour votre site web .
Dans le cas contraire, il vous suffit d’ajouter quelques lignes de code dans le fichier .htaccess
Dans l’entête HTTP X-Robots-Tag, vous aurez simplement besoin d’ajouter un “noindex” à la suite de cet entête.
Notez que cette solution est surtout intéressante pour désindexer des pages spécifiques, comme les PDF, les images ou les pages web sans code source.
Ce n’est donc pas la solution la plus adéquate, la plupart du temps.
La directive disallow dans votre robots.txt
Lorsqu’un moteur de recherche vient crawler votre site, la première chose qu’il va aller chercher est votre fichier robots.txt.
C’est dans ce fichier que les directives sont indiquées, et c’est donc ici que vous pourrez plus spécifiquement bloquer l’accès au moteur de recherche.
Faites attention cependant : vous bloquez l’accès au crawl pour les adresses renseignées, mais si vos pages ont déjà été référencées, elles ne disparaîtront pas instantanément des moteurs de recherche pour autant. C’est simplement qu’elles ne seront plus actualisées dans l’index des moteurs de recherche.
Pour voir à quoi ressemble votre fichier robots.txt, la plupart du temps, il suffit de vous rendre sur l’adresse : https://votresite.fr/robots.txt
Vous y verrez toutes les directives données aux Googlebots et autres robots d’indexation.
Pour accéder à votre fichier robots.txt vous devez accéder au FTP de votre site. S’il existe déjà, vous devrez trouver ce fichier robots.txt à la racine de votre site web. Sinon, vous pouvez le créer en le nommant bien “robots.txt”. Dans ce fichier robots.txt, vous devez avoir les éléments suivants :
- Le robot auquel d’adresse ce fichier (ligne 1)
- Les répertoires / fichiers auxquels l’agent est autorisé à accéder (ligne 2)
- Les répertoires ou fichiers que vous souhaitez bloquer à l’agent (ligne 3)
À noter que la ligne 2 et 3 ne sont pas fixes, l’exemple ci-dessous est un exemple, mais vous pouvez les interchanger ou supprimer la ligne “allow” si vous ne souhaitez pas indexer votre site par exemple.
user-agent: *
Disallow: /wp-admin/
allow: /wp-admin/admin-ajax
ou, si votre site est en préproduction, vous souhaitez bloquer l’accès à toutes vos pages :
user-agent: *
Disallow: /
Il y a plusieurs manières de désindexer des éléments dans ce fichier :
1. Bloquer le crawl d’une catégorie à page entière (incluant toutes les URLs « filles »)
Disallow: */catégorie/*
2. Bloquer le crawl d’une catégorie, sauf d’une page
Disallow: */catégorie/*
allow: */catégorie/sous-page/*
3. Bloquer un type de fichier en particulier
Disallow: /*.pdf
Le fichier robots.txt fonctionne plus ou moins comme les règles en CSS : les règles les plus spécifiques prennent le pas sur les règles plus générales.
Si votre site est sur WordPress, vous avez une option dans les paramètres : “Demander aux moteurs de recherche de ne pas indexer ce site”. Dans ce cas, cela ajoute simplement une directive dans le fichier robots.txt : si tel est votre cas, inutile de modifier votre fichier, vous pouvez directement bloquer l’indexation sur l’ensemble de votre site via cette option.
La protection par mot de passe
Technique efficace si vous ne souhaitez pas que votre site soit crawlé par les moteurs de recherche, vous pouvez attribuer un mot de passe pour autoriser l’accès.
Cette méthode est également utile dans le cas où vos pages n’ont encore jamais été indexées.
Pour procéder de cette manière, vous devez modifier votre fichier .htaccess et créer un fichier .htpasswd. Dans le .htaccess, indiquez le bout de code suivant :
AuthType Basic
AuthName "Identifiez-vous avant de poursuivre"
AuthUserFile /path/to/.htpasswd
Require valid-user
Si vous souhaitez en savoir plus, le site codeur.com a fait un excellent article sur le sujet
La suppression temporaire via la Google Search Console
Cette option existe même si ce n’est pas vraiment la plus intéressante. En effet, vous pouvez directement proposer une suppression temporaire au travers de la Google Search Console, mais seulement Google prendra en compte cette directive
Pour procéder :
- Connectez-vous à votre interface Google Search Console
- Cliquez sur “Suppressions”
- Dans l’onglet Suppressions temporaires, cliquez sur “Nouvelle Demande”
- Ajoutez l’URL concernée et choisissez si vous souhaitez supprimer seulement cette URL où l’ensemble de la catégorie.

Laquelle de ces solutions est la plus intéressante ?
De mon point de vue, les solutions les plus intéressantes sont la modification du robots.txt et l’intégration de la balise meta noindex. Il s’agit à la fois des directives les plus simples (et les moins dangereuses) à mettre en place, mais c’est également celles qui vous permettent le plus de flexibilité :
- La balise meta noindex vous permet d’empêcher des pages spécifiques d’être de nouveau indexées
- Le robots.txt permet plus ou moins de tout contrôler. En fait, il ne sert qu’à ça, et remplit très bien sa fonction. De plus, si vous êtes amené à modifier de nombreuses pages pour leur attribuer la balise noindex, il peut être plus intéressant de passer directement par le fichier robots.txt, ce qui sera beaucoup moins chronophage. En plus de ces éléments, il permet d’indiquer l’emplacement de votre fichier Sitemap.xml
Comment supprimer le référencement déjà effectué sur mon site ?
Supprimer votre référencement signifie que toutes vos pages n’apparaissent plus lorsque vous faites une recherche Google sur des mots-clés où vous étiez positionné auparavant.
Il y a peu d’intérêts à supprimer un référencement déjà établi sur votre site. Cependant, pour ne plus apparaître dans Google, il est nécessaire de lui indiquer que vous ne souhaitez pas que vos pages soient indexées dans sa base de données.
Faites attention cependant, indiquer aux moteurs de recherche que vous ne souhaitez plus voir vos pages indexées ne signifie pas systématiquement qu’elles ne seront plus référencées.
Vos pages déjà positionnées peuvent très bien rester positionnées dans Google. De la même manière, des pages supprimées peuvent très bien rester positionner dans les pages de résultats des moteurs de recherche mais simplement renvoyer une erreur 404.
Pour supprimer le référencement de tout ou partie de votre site, vous devrez donc être patient, car cela ne se fait pas du jour au lendemain mais peut prendre plusieurs semaines ou mois le temps d’être « déclassé » de Google.
Mes pages ne se référencent pas, pourquoi ?
Si vos pages ne se référencent pas contre votre gré, cela peut venir de divers problèmes :
- Votre page présente des soucis de crawlabilité, ou bien le budget crawl est dépassé.
- Les robots ont été bloqué à cause d’un mauvais paramétrage des balises noindex ou du fichier robots.txt
- Les robots ont été bloquées à cause d’un plugin
- Vos pages proposent peu de contenus, et qui plus est de contenu de haute qualité, ce qui indique à Google que vous n’apportez aucune plus-value à l’internaute.
Il existe un tas de raisons pour lesquelles vos pages ne se référencent pas. Malheureusement, il peut être compliqué de déterminer le problème si cela ne provient pas d’un mauvais paramétrage des fichiers ou balises : le meilleur moyen de savoir, c’est de faire un audit SEO.

Besoin d'un audit SEO ?
TPME, indépendants ou grands comptes, prenons 10 minutes pour parler du référencement de votre site web 
FAQ
Est-ce handicapant de chercher à ne pas référencer une page ?
Pas nécessairement.
En fait, il y a de bonnes raisons qui peuvent vous pousser à ne pas référencer une page : un site en préproduction, un fichier privé ou simplement des documents qui ne devraient pas être accessibles via les moteurs de recherches sont de bonnes raisons.
Comment tester son fichier robots.txt ?
Si vous souhaitez vérifier votre fichier robots.txt, et notamment voir si vous avez accès à certaines pages ou non, vous pouvez utiliser l’outil Google Webmaster Tools, qui est gratuit.